Nel mondo dello sviluppo software, l’ottimizzazione delle prestazioni è una priorità costante. La capacità di valutare e misurare come una determinata applicazione (o API) si comporta sotto carico è cruciale per garantire una performance affidabile, specie quando la soluzione interessa tecnologie web e coinvolge dunque un server remoto. Tra i numerosi strumenti a disposizione degli sviluppatori per le attività di testing, ApacheBench è noto per la semplicità e la versatilità che lo caratterizzano.
Rapido e di facile utilizzo, permette di valutare le prestazioni di un server web o di un’API attraverso una serie di richieste HTTP concorrenti. Proprio a causa della sua struttura essenziale, ApacheBench è un ottimo punto di partenza per comprendere le dinamiche del benchmarking e ottenere rapidamente informazioni cruciali sulle prestazioni del servizio web. Allo stesso tempo è importante riconoscere che esistono molte soluzioni più avanzate e sofisticate per simulare scenari di utilizzo reali e complessi, alcune delle quali vanno oltre la semplice esecuzione di richieste concorrenti e consentono ad esempio di modellare il comportamento degli utenti in modo più accurato. Si segnalano a riguardo strumenti come Apache JMeter, Gatling, o locust.io.

ApacheBench: informazioni essenziali
Ab è spesso incluso nel pacchetto di installazione dei server HTTP Apache, ed è essenzialmente uno strumento molto compatto eseguibile da linea di comando. Online si trovano svariate guide all’installazione su diversi sistemi operativi. In questo articolo si riportano degli esempi eseguiti in Windows, ambiente per il quale è sufficiente individuare ed eseguire (da CLI) il file ab.exe. La sintassi dei comandi rimane comunque la medesima per l’esecuzione dei test in ambiente Unix.
Nonostante la sua sostanziale semplicità, Ab supporta diversi parametri per la personalizzazione del test da eseguire. Una lista completa è riportata alla pagina di documentazione ufficiale:
In questo articolo eseguiremo dei test relativamente semplici, per i quali sarà necessario specificare tre parametri:
-
-n: numero di richieste totali -
-c: numero di richieste concorrenti -
<url>: indirizzo del servizio web da testare
il comando apparirà dunque come segue:
ab.exe -n NUM_REQ -c NUM_CON http://testing-service-url.exampleScenario di test
Per eseguire alcuni test, abbiamo predisposto un endpoint dedicato sulla piattaforma di hosting ATLED delnHost. Il web server utilizza LiteSpeed, che è strutturalmente molto simile ad Apache. All’indirizzo definito per i test risponde uno script che esegue alcuni calcoli numerici e fornisce poi una risposta positiva (200). Al fine di poter osservare anche la differenza di prestazioni in caso di codice più dispendioso, è possibile passare un queryparam che definisce un fattore di complessità dei calcoli da svolgere.
Le chiamate saranno quindi da indirizzarsi al seguente URL:
http://delnhost.pro/testing/?n=COMPLEXITY_FACTORcon opportuna sostituzione di un valore intero come COMPLEXITY_FACTOR.
Definizione dei test-case
Ogni attività di test, specialmente se a scopo di misura delle prestazioni, necessita di una chiara strategia di testing. Ciò significa definire quante prove svolgere, come svolgerle, con che parametrizzazioni, ma anche chiarire sin dall’inizio come andranno interpretati i risultati.
Per fare un esempio banale, si potrebbe d’istinto credere che se 100 richieste devono essere servite insieme, allora il test vada eseguito con concurrency = 100. In questo ragionamento si sta però ignorando che ogni richiesta è un evento che dura pochi millisecondi (ipotizziamo 50), e se decidiamo che 100 sono le richieste per secondo, la contemporaneità effettiva da gestire sarà solamente di (100 x 50) / 1000 = 5.
Ciò che è necessario fare, dunque, per condurre un’efficace attività di benchtesting, è porsi una domanda chiara, e definire una strategia efficace per rispondervi sperimentalmente. Nel nostro caso, cercheremo di rispondere alla seguente domanda:
Quante richieste al secondo posso gestire per far sì che meno del 5% di queste superi un tempo limite di 500ms?
La procedura per rispondere a questa domanda è molto semplice, e si può riassumere nei seguenti passaggi:
- Definizione dei parametri costanti (numero di richieste, tempo massimo di esecuzione, indice di complessità del carico da elaborare);
- Esecuzione di un primo test con concurrency uguale ad 1;
- Esecuzione di una serie di test con concurrency crescente;
- Osservazione del valore di concurrency che causa il superamento del limite di performance imposto (in questo caso, il valore che fa salire sopra al 5% il numero di richieste che impiegano più di mezzo secondo);
- Calcolo delle richieste per secondo in base alla media dei tempi di esecuzione ottenuti nel test-limite del punto precedente.
Prima di iniziare
Alcuni concetti sono importanti da tenere a mente nel procedere con questo tipo di prova. Va innanzitutto considerato che questo test esegue una serie di reali richieste che partono dal proprio PC e raggiungono il server remoto. Dunque, ogni prova può essere alterata dalla situazione di rete, soprattutto nel caso in cui il server e il client non si trovino in locale.
Allo stesso tempo, un alto numero di richieste (soprattutto concorrenti) potrebbe essere visto dal server come un’attività malevola, e potrebbe causare l’inclusione del proprio IP in una blacklist, o scatenare altri meccanismi di protezione. Vanno dunque prese le corrette precauzioni per evitare problemi di questo tipo.
Infine, è bene ricordare che lo scopo di questo test è di introdurre il concetto di benchmarking, e non di simulare una complessa situazione di richieste web generate – ad esempio – dal traffico di un dato numero di utenti. L’esito della prova fornirà dunque la mera misura di quante singole richieste possono essere servite da questo stack e da questo script in un secondo.
Esecuzione dei test di esempio
Decidiamo dunque di procedere iterando dei test caratterizzati da un numero di richieste pari a 100. La prima prova avrà ovviamente la concurrency fissata ad 1, valore che crescerà nelle prove successive fino al superamento del valore-soglia identificato.
Per l’osservazione della soglia (che ricordiamo essere il superamento del 5% di richieste servite in un tempo maggiore o uguale a 500ms), possiamo sfruttare l’apposita sezione della schermata di risultato, titolata “Percentage of the requests served within a certain time”.

Si noti che un numero consistente di richieste è segnalato come “failed”, ma che la totalità dei fallimenti rientra nella categoria “length”. Questo è dovuto alla dinamicità della pagina, che ritorna un contenuto html simile ma non sempre identico. Di conseguenza, Ab nota la differenza tra la lunghezza delle risposte e segnala alcune di esse come errori. Si può ovviare a questo disturbo includendo nel comando l’opzione -l, appositamente predisposta per pagine dinamiche.
Risultati
Si riportano di seguito i risultati raccolti in una sessione di 20 test.
| Concurrency | 95% best time | Outcome |
|---|---|---|
| 1 | 73 | Within time limit |
| 2 | 78 | Within time limit |
| 3 | 97 | Within time limit |
| 4 | 129 | Within time limit |
| 5 | 162 | Within time limit |
| 6 | 201 | Within time limit |
| 7 | 228 | Within time limit |
| 8 | 254 | Within time limit |
| 9 | 290 | Within time limit |
| 10 | 327 | Within time limit |
| 11 | 363 | Within time limit |
| 12 | 381 | Within time limit |
| 13 | 428 | Within time limit |
| 14 | 443 | Within time limit |
| 15 | 476 | Within time limit |
| 16 | 521 | Out of time limit |
| 17 | 537 | Out of time limit |
| 18 | 565 | Out of time limit |
| 19 | 602 | Out of time limit |
| 20 | 639 | Out of time limit |
Conclusioni
Si nota con chiarezza che la tendenza delle prestazioni è lineare, e si può individuare a 15 la soglia di concurrency oltre a quale le prestazioni dei best 95% degradano sotto al limite imposto.
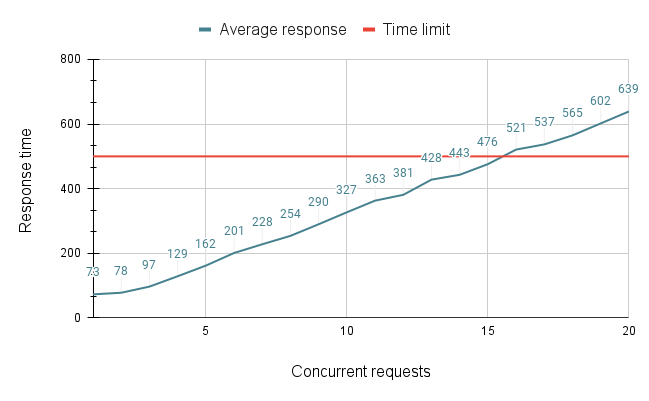
Dato che il tempo medio di risposta con la concurrency limite di 15 è pari a 489ms, si può infine definire il numero massimo di richieste gestibili al secondo attraverso il semplice calcolo che segue:
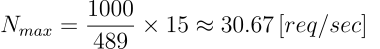
In conclusione si potrà dunque rispondere alla domanda iniziale affermando che
In condizioni ordinarie, l’API può gestire fino ad un massimo di 30 richieste al secondo facendo sì che meno del 5% di queste superino un tempo limite di 500ms.